
全国中心













 AI智能应用开发
AI智能应用开发 AI大模型开发
AI大模型开发 AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+
AI嵌入式+ AI大数据开发
AI大数据开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作运营
AI视频创作运营
免费领取黑马程序员AI通道专属星级课程资料

更新时间:2019-08-30 来源:黑马程序员 浏览量:
1. 前置知识
什么是黑色星期五?
黑色星期五可以简单理解为国外的双十一,是指十一月第四个星期五,各大商场都会推出大量的打折和优惠活动的日子。
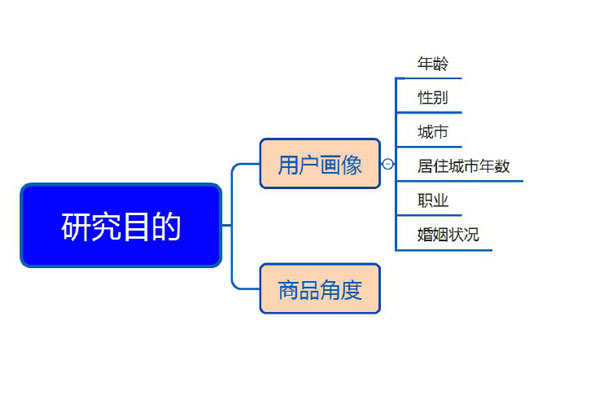
数据EDA 的研究目的是什么?
数据分析不是为了分析而分析,而是要通过数据分析来达到某种目的。对黑色星期五销售数据进行分析,是希望通过数据分析来更好地了解客户购买行为。同时可以为算法建模提供好数据支持。
项目简介
黑色星期五数据BlackFriday 探索性分析EDA该数据集包括从零售商店获得的销售交易数据。这是一个帮我们探索和扩展特征工程技术和逐渐了解多角度购物经验的经典数据集。数据集有537576 行12 列。
数据集
见文件数据集有537576 行12 列

环境需求
Anaconda2 + pycharm + numpy + pandas + matplotlib + scikitlearn + RF
运行结果
代码实现:
#TODO: BlackFriday EDA
#关于一家零售店黑色星期五的55 万次观测数据
#它包含不同类型的变量,无论是数值变量还是类别型变量
# todo:1.Libraies
# 我们将会使用Pandas,Numpy,Seaborn 和Matplotlib 库进行分析
#Warnings
import warnings
warnings.filterwarnings("ignore")
import pandas as pd
import numpy as np
#可视化
import seaborn as sns
import matplotlib.pyplot as plt
import os
# print os.listdir("E:\Python\BlackFriday") # To return the
which files list containdec
sns.set(style="darkgrid")
# plt.rcParams["patch.force_edgecolor"]= True # matplotlib
中rcParams 主要用来设置图像像素,画图的分辨率,大小等信息
# patch.force_edgecolor 打开全球的边缘
#TODO:数据加载与特征提取
df=pd.read_csv("BlackFriday.csv")
# print df.head(2)
# User_ID Product_ID Gender Age Occupation
City_Category \
# 0 1000001 P00069042 F 0-17 10
A
# 1 1000001 P00248942 F 0-17 10
A
#
# Stay_In_Current_City_Years Marital_Status
Product_Category_1 \
# 0 2 0
3
# 1 2 0
1
#
# Product_Category_2 Product_Category_3 Purchase
# 0 NaN NaN 8370
# 1 6.0 14.0 15200
# print df.info()
# print df.shape
# RangeIndex: 537577 entries, 0 to 537576
# Data columns (total 12 columns):
# User_ID 537577 non-null int64
# Product_ID 537577 non-null object
# Gender 537577 non-null object
# Age 537577 non-null object
# Occupation 537577 non-null int64
# City_Category 537577 non-null object
# Stay_In_Current_City_Years 537577 non-null object
# Marital_Status 537577 non-null int64
# Product_Category_1 537577 non-null int64
# Product_Category_2 370591 non-null float64
# Product_Category_3 164278 non-null float64
# Purchase 537577 non-null int64
# dtypes: float64(2), int64(5), object(5)
# memory usage: 49.2+ MB
# None
# (537577, 12)
#TODO: 缺失值的处理
total_miss=df.isnull().sum() #对应特征缺失值总数
# print total_miss
# User_ID 0
# Product_ID 0
# Gender 0
# Age 0
# Occupation 0
# City_Category 0
# Stay_In_Current_City_Years 0
# Marital_Status 0
# Product_Category_1 0
# Product_Category_2 166986
# Product_Category_3 373299
# Purchase 0
# dtype: int64
# print total_miss
per_miss= total_miss/df.isnull().count() # 每列对应特征
的nan 数/ 所有特征nan 乘以100 对应特征的缺失比值
# print total_miss/df.isnull().count()*100 # 每列对应特征的
nan 数/ 所有特征nan 乘以100
# User_ID 0.000000
# Product_ID 0.000000
# Gender 0.000000
# Age 0.000000
# Occupation 0.000000
# City_Category 0.000000
# Stay_In_Current_City_Years 0.000000
# Marital_Status 0.000000
# Product_Category_1 0.000000
# Product_Category_2 31.062713
# Product_Category_3 69.441029
# Purchase 0.000000
# dtype: float64
missing_data = pd.DataFrame({'Total missing':total_miss,
'% missing':per_miss})
# print missing_data
# print missing_data.sort_values(by='Total
missing',ascending=False).head(3)
# % missing Total missing
# Product_Category_3 0.694410 373299
# Product_Category_2 0.310627 166986
# User_ID 0.000000 0
#由于大多数产品只属于一个类别,所以少一些产品有第二个类别是
有意义的,更不用说第三个类别了。
# TODO :唯一值
#探讨数据中特征中的唯一值。总共有537577
# print "Unique Values for Each Feature:\n"
# print df.columns
# Index([u'User_ID', u'Product_ID', u'Gender', u'Age',
u'Occupation',
# u'City_Category', u'Stay_In_Current_City_Years',
u'Marital_Status',
# u'Product_Category_1', u'Product_Category_2',
u'Product_Category_3',
# u'Purchase'],
# dtype='object')
# for i in df.columns: # i 对应就是columns 中的每一列
# print i,':',df[i].unique()
#todo:关于产品信息
# print "Number of products:",df['Product_ID'].unique()
# print "Number of products
Numbers:",len(df['Product_ID'].unique().tolist())
# print "Number of
categories:",df["Product_Category_1"].unique().max()
# print "Highest and lowest
purchase:",df['Purchase'].max(),',',df['Purchase'].min()
# Number of products: ['P00069042' 'P00248942'
'P00087842' ..., 'P00038842' 'P00295642'
# 'P00091742']
# Number of products Numbers: 3623
# Number of categories: 18
# Highest and lowest purchase: 23961 , 185
#todo:关于买家信息
# print "Number of shoppers:",df['User_ID'].unique()
# print "Shoppers 数
量:",len(df['User_ID'].unique().tolist())
# print "Years in
city:",df['Stay_In_Current_City_Years'].unique()
# print "Age Group:",df['Age'].unique()
# Number of shoppers: [1000001 1000002 1000003 ..., 1004113
1005391 1001529]
# Shoppers 数量: 5891
# Years in city: ['2' '4+' '3' '1' '0']
# Age Group: ['0-17' '55+' '26-35' '46-50' '51-55' '36-45'
'18-25']
#TODO:Gender
#首先,通过查看每个条目的数量来确定数据是否按性别均匀分布;
count_m=df[df['Gender']=='M'] #在DataFrame 中选择性别为M
的所有数据
# print df['Gender']=='M'
# print count_m
count_m_count=df[df['Gender']=='M'].count()
count_m_count=df[df['Gender']=='M'].count()[0]
# print count_m_count
# User_ID 405380
# Product_ID 405380
# Gender 405380
# Age 405380
# Occupation 405380
# City_Category 405380
# Stay_In_Current_City_Years 405380
# Marital_Status 405380
# Product_Category_1 405380
# Product_Category_2 280741
# Product_Category_3 127346
# Purchase 405380
# dtype: int64
# User_ID Product_ID Gender Age Occupation
City_Category \
# 4 1000002 P00285442 M 55+ 16
C
# 5 1000003 P00193542 M 26-35 15
A
# 6 1000004 P00184942 M 46-50 7
B
# 7 1000004 P00346142 M 46-50 7
B
# 8 1000004 P0097242 M 46-50 7
B
# 9 1000005 P00274942 M 26-35 20
A
# print
"count_m_count=df[df['Gender']=='M'].count()[0]:",df[df['Ge
nder']=='M'].count()[0]
#count_m_count=df[df['Gender']=='M'].count()[0]: 405380
count_f = df[df['Gender']=='F'].count()[0]
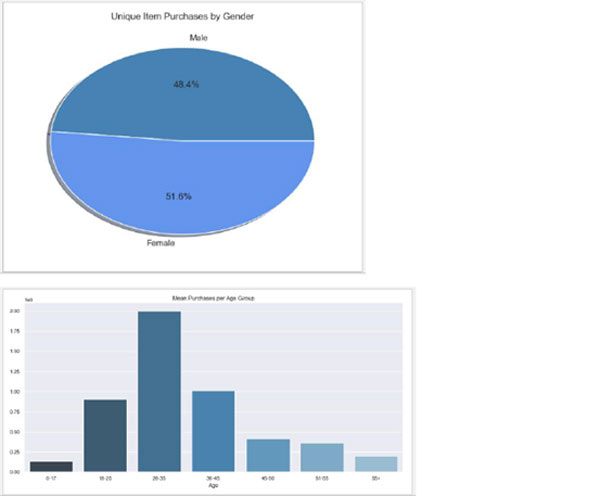
print "Number of male clients:",count_m_count
print "Number of female clients:",count_f
# 男客户数量: 405380
# 女客户数量: 132197
#我们可以看到记录的男性客户数量超过4 次记录的女性客户数量。
因此,通过使用比率而不是计算每条数据来分析性别将更加信息化。
让我们看看每个性别的多少每个人均消费
print "Female
Purchases:",round(df[df["Gender"]=='F']['Purchase'].sum()/c
ount_f)
print "Male
Purchases:",round(df[df["Gender"]=='M']['Purchase'].sum()/c
ount_m_count)
# Female Purchases: 8809.0 女性人均消费
# Male Purchases: 9504.0 男性分均消费
#图形绘制
# nunique() Return number of unique elements in the object.
plt.pie(df.groupby('Gender')['Product_ID'].nunique(),labels
=['Male','Female'],
shadow=True,
autopct='%1.1f%%',colors=['steelblue','cornflowerblue'])
plt.title('Unique Item Purchases by Gender')
plt.show()
print df.groupby('Gender')['Product_ID'].nunique()
# F 3358
# M 3582
# Name: Product_ID, dtype: int64
#虽然差不多,但女性确实购买了比男性更多的产品。现在,让我们
根据产品类别分析每个性别购买的比例。
#按照性别进行分组
print "===================="
# print df[df['Gender'] == 'M']
# User_ID Product_ID ... Product_Category_3
Purchase
# 4 1000002 P00285442 ... NaN
7969
# 5 1000003 P00193542 ... NaN
15227
# 6 1000004 P00184942 ... 17.0
19215
# 7 1000004 P00346142 ... NaN
15854
gender = df[df['Gender'] == 'M'][['Product_Category_1',
'Gender']] # 针对过滤为男性用户的数据进行选取
Product_Category_1 Gender
# print gender
# Product_Category_1 Gender
# 4 8 M
# 5 1 M
# 6 1 M
#todo:品类1 中的男性用户数量
gb_gender_m = df[df['Gender'] == 'M'][['Product_Category_1',
'Gender']].count()
print "gb_gender_m:\n",gb_gender_m
gb_gener_f = df[df['Gender'] == 'F'][['Product_Category_1',
'Gender']].count()
# print "gb_gender_f:\n",gb_gener_f
# gb_gender_m:
# Product_Category_1 405380
# Gender 405380
# dtype: int64
# gb_gender_f:
# Product_Category_1 132197
# Gender 132197
#连接并更改列名称
print "---------------------------------"
cat_bygender=pd.concat([gb_gender_m,gb_gener_f],axis=1)
# print cat_bygender
# 0 1
# Product_Category_1 405380 132197
# Gender 405380 132197
cat_bygender.columns=['M ratio','F ratio']
# print cat_bygender
# M ratio F ratio
# Product_Category_1 405380 132197
# Gender 405380 132197
#调整以比率
cat_bygender['M ratio'] = cat_bygender['M
ratio']/df[df['Gender']=='M'].count()[0]
cat_bygender['F ratio'] = cat_bygender['F
ratio']/df[df['Gender']=='F'].count()[0]
# print df[df['Gender']=='M'].count()
# User_ID 405380
# Product_ID 405380
# Gender 405380
# Age 405380
# Occupation 405380
# City_Category 405380
#Create likelihood of one gender to buy over the other
cat_bygender['Likelihood (M/F)']=cat_bygender['M
ratio']/cat_bygender['F ratio']
cat_bygender['Total Ratio'] = cat_bygender['M
ratio']+cat_bygender['F ratio']
cat_bygender.sort_values(by='Likelihood
(M/F)',ascending=False)
# print cat_bygender
#TODO:Age
# Age 值是字符串,我们现在对每个组进行编码,以便它们可以用机
器学习算法可以理解的整数值表示
#年龄组编码
df['Age_Encoded'] = df['Age'].map({'0-17':0,'18-25':1,
'26-35':2,'36-45':3,
'46-50':4,'51-55':5,
'55+':6})
prod_byage = df.groupby('Age').nunique()['Product_ID']
fig,ax = plt.subplots(1,2,figsize=(14,6))
ax = ax.ravel()
sns.countplot(df['Age'].sort_values(),ax=ax[0],
palette="Blues_d")
ax[0].set_xlabel('Age Group')
ax[0].set_title('Age Group Distribution')
sns.barplot(x=prod_byage.index,y=prod_byage.values,ax=ax[1]
, palette="Blues_d")
ax[1].set_xlabel('Age Group')
ax[1].set_title('Unique Products by Age')
plt.show()
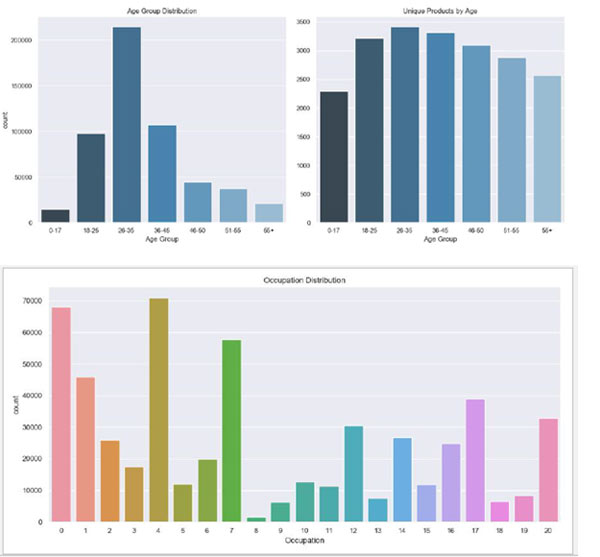
#很明显,客户中最大的年龄组是26-35 岁。有趣的是,就数量而言,
产品购买的分布在各年龄组之间差异不大。这意味着,虽然26-35
岁年龄组是最受欢迎的,但其他年龄组购买的几乎与他们一样多。但
这是否意味着在年龄组中花费的金额是相同的?让我们来看一下
spent_byage = df.groupby(by='Age').sum()['Purchase']
plt.figure(figsize=(12,6))
sns.barplot(x=spent_byage.index,y=spent_byage.values,
palette="Blues_d")
plt.title('Mean Purchases per Age Group')
plt.show()
#我们的数据清楚地表明,每个年龄组的资金数额与年龄组内的客户
数量成正比。这可能是商店的有价值的信息,因为它可能希望在未
来添加更多针对该年龄组的产品,或者可能致力于营销不同的项目以
增加其客户年龄组的更广泛的多样性。
#TODO: Occupation
# This sections draws some insights on our data in terms of the
occupation of the customers.
plt.figure(figsize=(12,6))
sns.countplot(df['Occupation'])
plt.title('Occupation Distribution')
plt.show()
plt.figure(figsize=(12,6))
prod_by_occ =
df.groupby(by='Occupation').nunique()['Product_ID']
sns.barplot(x=prod_by_occ.index,y=prod_by_occ.values)
plt.title('Unique Products by Occupation')
plt.show()
spent_by_occ = df.groupby(by='Occupation').sum()['Purchase']
plt.figure(figsize=(12,6))
sns.barplot(x=spent_by_occ.index,y=spent_by_occ.values)
plt.title('Total Money Spent per Occupation')
plt.show()
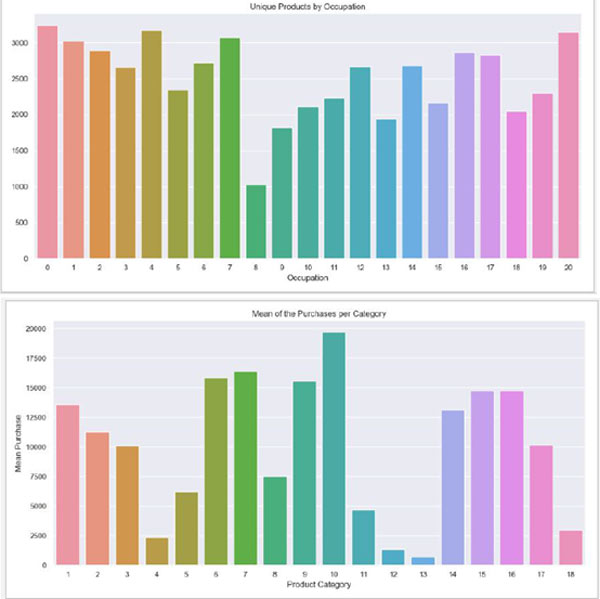
#再一次,每个职业所花费的平均金额的分配似乎反映了每个职业中
人数的分布。从数据科学的角度来看,这是幸运的,因为我们没有
使用奇怪或突出的功能。我们在年龄和职业方面的数据似乎很有意
义。
#TODO: Products
#这里,我们探索产品本身。这很重要,因为我们在此数据集中没有
标记的项目。从理论上讲,客户可以在4 台新电视或10,000 支笔上
花费5,000 美元。这种差异对商店很重要,因为他们的利润受到影
响。由于我们不知道这些项目是什么,让我们探索项目的类别。
plt.figure(figsize=(12,6))
prod_by_cat =
df.groupby('Product_Category_1')['Product_ID'].nunique()
sns.barplot(x=prod_by_cat.index,y=prod_by_cat.values,
palette="Blues_d")
plt.title('Number of Unique Items per Category')
plt.show()
#类别标签1,5 和8 显然具有最多的项目。这可能意味着商店以该项
目而闻名,或者该类别是广泛的。
category = []
mean_purchase = []
for i in df['Product_Category_1'].unique():
category.append(i)
category.sort()
for e in category:
mean_purchase.append(df[df['Product_Category_1']==e]['Purch
ase'].mean())
plt.figure(figsize=(12,6))
sns.barplot(x=category,y=mean_purchase)
plt.title('Mean of the Purchases per Category')
plt.xlabel('Product Category')
plt.ylabel('Mean Purchase')
plt.show()
#有趣的是,我们最受欢迎的类别并不是那些赚钱最多的类别。这似
乎是一个大商店,他们可能会意识到这一点。然而,对于可能不知
道的较小商店的情况,可以使用相同形式的分析,并且它可能非常有
用。
#TODO: Estimate of price and quantity of purchase
#由于“购买”功能暗示客户为某个项目的未知金额支付了多少钱,
因此我们大胆假设产品支付的最低购买金额是所述商品的价格
#最低购买量的产品
prod_prices =
df.groupby('Product_ID').min()['Purchase'].to_dict()
#现在,每个商品ID 的购买价值按人们可以购买的商品数量进行分
组。然后,下面计算的价格和数量是一个估计,但它将是一个非常
好的
def find_price(row):
prod = row['Product_ID']
return prod_prices[prod]
df['Price'] = df.apply(find_price,axis=1)
df['Amount'] = round(df['Purchase']/df['Price']).astype(int)




















.jpg)